Tkrzw-Dict: 統合英和辞書プロジェクト
概要
統合英和辞書プロジェクトは、オープンなデータを使って英和辞書を作り、それを元に様々なアプリケーションを作るプロジェクトです。現在、以下のアプリケーションが利用可能です。
- オンライン辞書検索システム
- Chrome拡張の辞書検索機能
- オンライン連想英単語帳: 初級編3600語、上級編9600語
- オンライン語彙力年齢診断
- オンライン発音記号検定
- Kindle用電子辞書: 英和辞書、和英辞書、英和例文辞書、英和代替辞書
辞書データの元となるオープンなデータとは、WordNet、日本語WordNet、Wiktionary英語版、Wiktionary日本語版、Wikipedia英語版、Wikipedia日本語版、EDict2、田中コーパス、Wikipedia日英京都関連文書対訳コーパス、Japanese-English Subtitle Corpus、CCAligned、Open American National Corpus、Common Crawlを指します。それらのデータはインターネットを介して無料で入手することができ、当該ライセンスに基づいて自由に利用することができます。
上述の各種辞書データを処理して単純なTSVデータに変換したものが以下のファイルです。独自のアプリケーションを作る際には、これらのデータを使うと便利でしょう。
- wordnet.tsv : WordNetの語義TSVファイル
- wiktionary-en.tsv : Wiktionary英語版の語義TSVファイル
- wiktionary-ja.tsv : Wiktionary日本語版の語義TSVファイル
- supplement.tsv : EDict2の語義TSVファイル
オンライン辞書検索システム
オンラインで辞書を検索するシステムを作りました。実際のサイトを利用してみてください。検索窓に英単語を入力し、「検索」ボタンを押せば、その英単語の語義が表示されます。検索窓に日本語を入力して検索すれば、その日本語を語義に含む英単語のリストが表示されます。すなわち、このシステムは英和辞書としても和英辞書としても利用できます。単語だけでなく、複数語からなるフレーズでも検索できます。さらに、スペルミスを吸収するための曖昧一致検索や、関連語を検索するための類語検索も実装されています。語の変化形で検索できる屈折索引も利用できます。
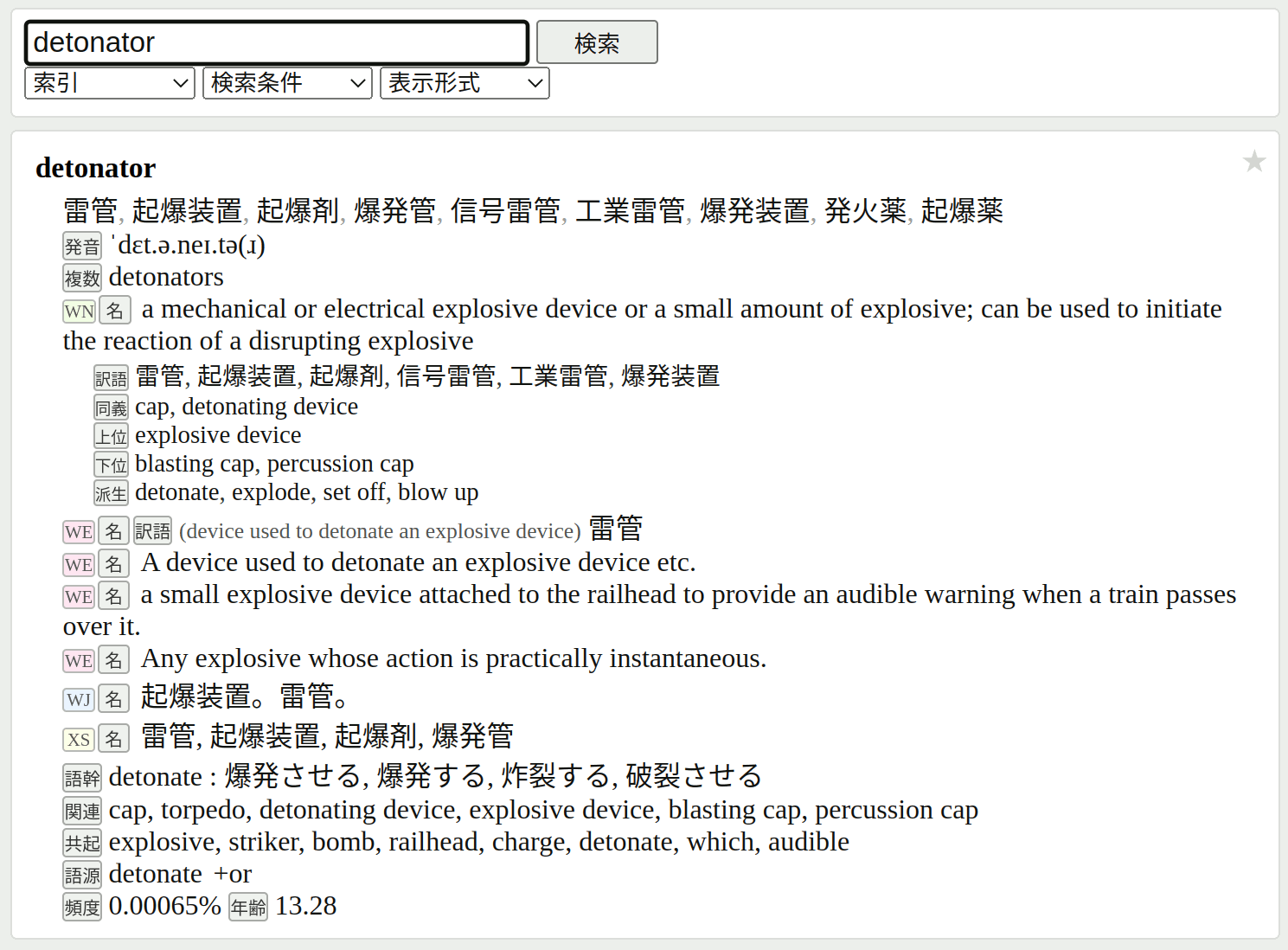
英文読解の際には英和辞書検索機能が頻繁に用いられますが、その際には曖昧一致検索や屈折索引が自動的に機能して、検索語を入力し直す手間を大幅に削減してくれます。英作文の際には、和英辞書検索機能が頻繁に用いられますが、その際には類語検索を利用すると、所望の英単語を探す手間を大幅に削減できます。英語学習を補助する機能として、覚えるべき語句をレベル別に一覧できる等級一覧機能や、任意の英文中の全ての語句にルビを振って和訳を表示する注釈機能もあります。
この辞書の内容は、日本語の訳語と英語の語義説明が併記してあることが特徴です。初学者は訳語だけ見て、大体の意味を素早く理解することができる一方、上級者は英語の語義説明や例文を読んで詳細な意味を知ることができます。基本となる語を調べるだけで、語幹や派生語や熟語の意味も表示されるのが便利です。例えば、「mindful」を引けば「mind : 精神, 念頭, 心」も併記されますし、「mind」を引けば「minded : 志向の, 熱心な」「in mind : 念頭に置く」なども表示されます。
検索結果の各見出し語の星マークをクリックすると、その語はブラウザに記憶されます。辞書のトップページにある星アイコンをクリックすると、星がつけられた語の一覧が表示されるので、そこで検索語の復習をすることができます。英文を読みながら未知語を調べて後で復習すれば、着実に語彙力を強化できます。

Chromeブラウザの拡張機能をインストールしてブラウザ上でポップアップ検索を行うこともできます。このZIPファイルをダウンロードして、展開したディレクトリを拡張機能のディベロッパーモードでインストールしてください。画面右上の「EJ」アイコンをクリックすれば、オンライン辞書の全ての機能を使うことができます。

オンライン連想英単語帳
似た単語をまとめて一括して覚えるための単語集を作りました。初級編と上級編の二種類があります。辞書の中から、実際の英文中に登場する頻度が高い単語を抽出したので、重要単語を集中的に覚えることができます。
さらに、関連する語彙をまとめて覚えるための工夫をしています。例えば、見出し語「part」には、「partly」「partial」「parted」といった派生語とその意味が記載され、一気に覚えることができます。また、見出し語同士を意味や用法で分類しているので、「error」「mistake」「fault」「incorrect」などの語も関連付けて覚えることができます。関連性のない語とその意味を無作為な順序で暗記するよりは、関連のある語を連想しながら記憶する方が遥かに効率がよくなります。
連想英単語集は、意味を覚えるための学習ページの他に、意味を覚えたか確認するための確認ページからなります。確認ページでは、英単語だけを表示して訳語を思い出せるか確認したり、訳語だけを表示して英単語を思い出せるか確認したりすることができます。
Kindle用電子辞書
Kindle端末の電子辞書として使える英和辞書と和英辞書を作りました。電子書籍の本文にある語句を長押しするだけで、その語句を辞書で調べることができます。Kindleの実機(無印Kindle、Paperwhite、OASIC、Voyage等)のいずれもで利用できます。英和辞書のMOBIファイルと和英辞書のMOBIファイルと英和例文辞書のMOBIファイルと英和代替辞書のMOBIファイルをダウンロードして、Kindle実機の書籍データフォルダにコピーしてください。おそらくdocumentsというフォルダの中です。documentsの中にdictionariesというフォルダがある場合、そこに入れても構いません。その後、辞書メニューから、英語の辞書として「Union English-Japanese Dictionary」または「Union Example EJ Dictionary」または「Union Fallback EJ Dictionary」を、日本語の辞書として「Union Japanese-English Dictionary」を設定します。英和辞書の語義説明の部分を例文とその対訳に置き換えた英和例文辞書MOBIファイルもあります。英和辞書と適宜切り替えながら使ってください。

パソコンや携帯端末で動くKindle for PC/Mac/Android/iOSアプリでも統合辞書を使うことができます。Kindleアプリではカスタム辞書を追加する公式の方法はないので、デフォルトでインストールされる辞書を上書きする方法を採ります。まず、普通にKindleアプリを使って、プログレッシブ英和辞典とプログレッシブ和英辞典をインストールします。それらの辞書データはKindleアプリのデータフォルダに保存されます。Macの場合、データフォルダは~/Library/Application Support/Kindle/My Kindle Contentです。その中に、英和辞書であればB005FNK002、和英辞書であればB00DQB1G3Kが名前に付くディレクトリがあります。それらの中にある拡張子がazwかprcかmobiのファイルが辞書データです。それを置き換えます。英和辞書はこのMOBIファイルで、和英辞書はこのMOBIファイルで置き換えます。拡張子をprcやazwに変えることにっても問題ありません。その後、Kindleアプリを再起動すると、デフォルトの辞書の内容が統合英和辞書のものに入れ替わります。元に戻すには、インストールしたMOBIファイルを消してください。デフォルトの辞書が自動的にダウンロードされます。
Kindle実機用の辞書データとKindleアプリ用の辞書データが分かれているのは、後者ではデフォルトの辞書のASIN属性と同じものを設定する必要があるためです。Kindle実機でアプリ用の辞書データを使ってしまうと、デフォルトの辞書が機能しなくなってしまいます。Kindleアプリで実機用の辞書データを使ってしまうと、デフォルトの辞書が再ダウンロードされて上書きされてしまいます。
オンライン語彙力年齢診断
辞書データを使って英語の語彙力の診断を行うシステムもあります。こちらのサイトにアクセスしてください。質問に答えていくと、回答者の語彙力がネイティブスピーカの何歳に相当するのかがわかります。
オンライン発音記号検定
辞書データを使って英語の発音記号の読解力を測るシステムもあります。こちらのサイトにアクセスしてください。発音記号を見てそれに該当する英単語を答えていくことで、発音記号の読解力を測り、また練習に使って向上させることができます。
インストール
ここからは、開発者向けの内容を説明する。本パッケージはUNIX系のOSで動作します。また、DBMライブラリであるTkrzwとそのPythonインターフェイスに依存する。所定の手順に基づき、それらを予めインストールしておくこと。
本パッケージのコードベースはGitHubにて公開されている。以下のコマンドで全てのコードを入手できる。
辞書データはこのアーカイブファイルをダウンロードすることで入手できる。それを展開すると、以下のファイルが得られる。
- union-body.tkh : 英和辞書本体
- union-tran-index.tkh : 和英検索用の索引
- union-infl-index.tkh : 屈折検索用の索引
- union-keys.txt : 英和辞書のキーのリスト
- union-tran-keys.txt : 和英索引のキーのリスト
- union-examples.tsv : 見出し語と例文とその和訳のリスト
検索用のプログラムはWebサーバ上で動作するCGIスクリプトとして実装されている。よって、Webサーバをインストールし、CGIスクリプトの実行設定をする必要がある。その上で、以下のプログラムを所定の場所に配置する。また、Pythonのregexモジュールをインストールする。
- search_union.py
- tkrzw_union_searcher.py
- tkrzw_dict.py
search_union.pyをCGIスクリプトとして実行可能にし、それにアクセスすると検索機能が利用できる。拡張子をCGI等に変えても良い。辞書データの各種ファイルは同一ディレクトリに置いてあることを前提とするが、search_union.py内のCGI_DATA_PREFIXという変数の値を変更することでファイルの位置や名前を変更できる。
search_union.pyはコマンドラインツールとしても使うことができる。検索語は引数として指定する。
--data_prefixオプションで辞書データの接頭辞を指定できる。デフォルトは "union" であり、データファイルとして "union-body.tkh"、"union-tran-index.tkh"、"union-infl-index.tkh"、"union-keys.txt"、"union-tran-keys.txt" を読み込むことになる。
--indexオプションは索引のモードを指定する。引数として以下の値のどれかを指定する。
- auto : 自動選択(デフォルト)。検索語が日本語の文字を含まなければ英和索引、含めば和英索引を用いる。
- normal : 英和索引を用いる。"run" などで検索する。
- reverse : 和英索引を用いる。"走る" などで検索する。
- inflection : 英和の屈折索引を用いる。"ran" や "running" で "run" が探せる。
- grade : 等級索引を用いる。検索語に等級の数値「1」などを指定する。
- annot : 英和の注釈処理を行う。検索語に "This is a pen." などの英文を指定する。
--searchオプションは検索のモードを指定する。引数として以下の値のどれかを指定する。
- auto : 自動選択(デフォルト)。先に完全一致を試し、該当がなければ類語展開を行う。
- exact : 完全一致。見出し語が検索語と完全一致するものが該当する。
- prefix : 前方一致。見出し語が検索語で始まるものが該当する。
- suffix : 後方一致。見出し語が検索語で終わるものが該当する。
- contain : 中間一致。見出し語が検索語を含むものが該当する。
- word : 単語一致。見出し語が検索語を単語として含むものが該当する。
- edit : 曖昧一致。見出し語の綴りが検索語の綴りと似ているものが該当する。
- related : 類語展開。見出し語が検索語と完全一致するものとその類語が該当する。
--viewオプションは表示のモードを指定する。引数として以下の値のどれかを指定する。
- auto : 自動選択(デフォルト)。該当件数に応じて表示形式が決定される。
- full : 最も詳細な語義を表示する。
- simple : 代表的な語義のみを表示する。
- list : 和訳のみを表示する。
配布された辞書データを検索して利用するだけであれば、ここまでのことだけを知っておけば問題ない。これ以降の記述は、辞書データや検索システムを改造したい人のみが読むべきである。
辞書データファイル
union-body.tkhは、辞書本体のデータを収めたDBMファイルである。Tkrzwのハッシュデータベースの形式である。キーは小文字に正規化された英語の検索語であり、値はその検索語に一致する見出し語の語義情報のリストをJSON形式で表現したものである。例えば、「japan」というキーに対しては「Japan」(=日本)と「japan」(=漆)という二つの見出し語の情報のリストが関連づけられる。以下のようなコマンドで中身を見ることができる。
各々の見出し語は、以下の属性を持つJSONの連想配列である。
- word : 正規化されていない見出し語
- pronunciation: IPA発音記号
- noun_plural : 名詞の複数形
- verb_singular : 動詞の三人称単数現在形
- verb_present_participle : 動詞の現在分子および動名詞
- verb_past : 動詞の過去形
- verb_past_participle : 動詞の過去分詞
- adjective_comparative : 形容詞の比較級
- adjective_superlative : 形容詞の比較級
- adverb_comparative : 副詞の比較級
- adverb_superlative : 副詞の比較級
- item : 語義のリスト
- probability : 文中に出現する確率。
- translation : 主な翻訳語のリスト。
- related : 主な関連語のリスト。
- cooccurrence : 主な共起語のリスト。
見出し語のitem属性は、以下の属性を持つJSONの連想配列のリストである。リスト内の要素の順序は、第一キーはラベル順である。第二キーは、WordNet由来のデータでは翻訳語の和文コーパスにおける頻度の降順であり、Wiktionary由来のデータでは元データにおける収録順である。
- label : wnはWordNetと日本語WordNet、データソースの名前。wjはWiktionary日本語版、weはWiktionary英語版
- pos : 品詞。noun、verb、adjective、adverb、pronoun、auxverb、preposition、determiner、article、interjection、conjunction、prefix、suffix、abbreviation
- text : 語義。サブセクションは "[-]" で区切り、サブサブセクションは "[--]" で区切り、サブサブサブセクションは "[---]" で区切る。
WordNet由来の見出し語のtext属性では、サブセクションの先頭に "[xxx]:" という形式で以下のラベルが付くことがある。
- translation : 日本語WordNetから得られた翻訳語のリスト
- synonym : 同義語のリスト
- antonym : 対義語のリスト
- hypernym : 上位語のリスト
- hyponym : 下位語のリスト
- synset : WordNetにおけるSynsetのアドレス
union-tran-index.tkhは、和英検索用の索引を収めたDBMファイルである。Tkrzwのハッシュデータベースの形式である。キーは小文字に正規化された日本語の検索語であり、値はその検索語を語義に含む英語の見出し語の正規化した文字列のリストをTSV形式で表現したものである。例えば「日本」というキーに対しては「japan」や「nippon」が関連づけられる。リスト内の要素の順序は、英文コーパスにおける頻度の降順である。
union-infl-index.tkhは、屈折検索用の索引を収めたDBMファイルである。Tkrzwのハッシュデータベースの形式である。キーは小文字に正規化された英語の屈折形であり、値はその屈折形を持つ語の原型の正規化した文字列のリストをTSV形式で表現したものである。例えば「better」というキーに対しては「well」と「good」が関連づけられる。リスト内の要素の順序は、英文コーパスにおける頻度の降順である。
union-keys.txtは、英和検索のキーのみを収めたテキストファイルである。英語の見出し語の正規化した文字列が行区切りで並べられている。リスト内の要素の順序は、英文コーパスにおける頻度の降順である。
union-tran-keys.txtは、和英検索のキーのみを収めたテキストファイルである。翻訳語の正規化した文字列が行区切りで並べられている。リスト内の要素の順序は、英文コーパスにおける頻度の降順である。
辞書データの構築
辞書データを自分で作るのは面倒なので、上述の辞書データのアーカイブファイルをダウンロードするのが推奨される。しかし、自分なりにカスタマイズしたい場合には、これ以降の記述を読む価値がある。辞書データの構築を行うプログラム群は、PythonのMeCabモジュールとnltkモジュールに依存するので、それらを予めインストールしておくこと。
英和辞書を作るにあたっては、英語や日本語の各語の頻度をデータベースにしておいて、それを用いて語の並び替えを行うことが望ましい。よって、Wikipedia英語版および日本版のデータをコーパスとして、フレーズと共起語の頻度を集計したデータベースを用意した。以下をダウンロードされたい。これらもパッケージに属するスクリプトで生成できるが、時間がかかるので推奨しない。
- enwiki-phrase-prob.tkh : 英語のフレーズの出現確率データベース
- enwiki-cooc-prob.tkh : 英語の単語毎の共起語の出現確率データベース
- jawiki-phrase-prob.tkh : 英語のフレーズの出現確率データベース
- jawiki-cooc-prob.tkh : 日本語の単語毎の共起語の出現確率データベース
辞書データを構築するにあたり、収録すべき各見出し語のデータを表現した「語義TSVファイル」を準備する必要がある。ファイル内では、各行が各見出し語の情報をTSV形式で表現し、TSVの各フィールドは「name=value」形式で、属性名とその値を表現する。属性名には以下のものがる。同じ属性が複数回現れても良い。
- word : 見出し語。語のレンマ(基本形)の文字列。小文字への正規化はしない。
- pronunciation_ipa : IPA発音記号
- pronunciation_sampa : SAMPA発音記号
- inflection_noun_plural : 名詞の複数形
- inflection_verb_singular : 動詞の三人称単数現在形
- inflection_verb_present_participle : 動詞の現在分子および動名詞
- inflection_verb_past : 動詞の過去形
- inflection_verb_past_participle : 動詞の過去分詞
- inflection_adjective_comparative : 形容詞の比較級
- inflection_adjective_superlative : 形容詞の比較級
- inflection_adverb_comparative : 副詞の比較級
- inflection_adverb_superlative : 副詞の比較級
- noun : 名詞の語義
- verb : 動詞の語義
- adjective :形容詞 の語義
- adverb : 副詞の語義
- pronoun : 代名詞の語義
- auxverb : 助動詞の語義
- preposition : 前置詞の語義
- determiner : 限定詞の語義
- article : 冠詞の語義
- interjection : 完投詞の語義
- conjunction : 接続詞の語義
- prefix : 接頭辞の語義
- suffix : 接尾辞の語義
- abbreviation : 略語の語義
- unkpos : 品詞不明の語義
Wiktionaryの日本語版および英語版の語義TSVファイルを生成するには、各々のXMLファイルをダウンロードしておいてから、以下のコマンドを実行すればよい。
wiktionary-ja.tsv $ bzcat ~/enwiktionary-latest-pages-articles.xml.bz2 | ./parse_wiktionary_en.py > wiktionary-en.tsv $ ./dump_wiktionry_trans.py wiktionary-en.tsv wiktionary-ja.tsv > wiktionary-tran.tsv ]]>
WordNetと日本語WordNetを統合した語義TSVファイルを生成するには、各々のアーカイブファイルを展開しておいてから、以下のコマンドを実行すればよい。
wordnet.tsv ]]>
規程の書式に準拠した語義TSVファイルを生成することで、任意のデータソースを使った辞書データを構築することができる。既成の以下ファイルをダウンロードしてから適当にカスタマイズしても良い。
- wordnet.tsv : WordNetの語義TSVファイル
- wiktionary-ja.tsv : Wiktionary日本語版の語義TSVファイル
- wiktionary-en.tsv : Wiktionary英語版の語義TSVファイル
- supplement.tsv : EDict2の語義TSVファイル
語の頻度データベースと語義TSVファイルが揃ったら、以下のコマンドを実行すると、英和辞書データの本体であるDBMファイルが構築できる。
その他の検索用ファイルは、以下の手順を踏めば生成できる。
EPUB形式の辞書ファイルを作成するには、以下の手順を踏む。
自動注釈機能
任意の英文中に現れる全ての語句の語義を辞書で調べて注釈として付与する機能がある。出力はHTMLデータである。辞書に該当の情報がある語句に対しては、和訳がルビとして振られ、詳細な語義情報がポップアップする付箋として付与される。検索用のCGIスクリプトもこの機能を備えるが、Web上で公開する機能にしては負荷が高すぎ、また出力のデータ量も大きすぎる。したがって、コマンドラインで同等のデータを生成して静的なHTMLファイルとして公開する方が良い。コマンドラインの入力としてはプレーンテキストとHTMLを受け付ける。プレーンテキストの中ではページ区切りの文字列を使って複数ページの文書を表現することができる。小説などの大きな文書を処理する際には、章ごとに複数のページに分けた方が、結果のデータの利便性が良くなる。典型的には、以下のような入力データを用意する。
上記のデータを "anne.txt" などとして保存したら、以下のコマンドを実行すると、ページ毎に注釈をつけたHTMLデータのファイルが出力され、またそれらのインデックス用のファイルも出力される。
語彙力年齢診断の構築
語彙力年齢診断のためのデータベースは、以下のコマンドで生成できる。
あとは、quiz_aoa.cgiをCGIスクリプトとして実行可能にし、またそのカレントディレクトリに "quiz-aoa-result" という名前でCGIスクリプトが書き込み可能なディレクトリを用意する。診断結果のデータはそのディレクトリの中にファイルとして作られる。
ライセンス
Tkrzw-dictのソースコードは平林幹雄が書いて、Google LLCが著作権を保持し、Apache license 2.0に基づいて頒布される。辞書データのライセンスについては各々のデータソースのサイトを参照されたい。著者に連絡するには <hirarin@gmail.com> にメールを送られたい。